中文 Literacy Speedrun II: Character Cyclotron
A great lie of learning Chinese is that reading in a meaningful sense is possible before an advanced level of study. By December of 2025 I had reached a vocabulary of about 1000 characters. On a strict token decoding basis this meant I had about 90% token coverage of typical text. On a semantic understanding basis - well - what does it mean to miss 10% of tokens?
The main @@@@@ is that one out of every ten words doesn't mean a dropped @@@@@ every now and then. Typically, the most important words get @@@@@, and key passages can @@@@@ new words above the base rate. The secondary @@@@@ is a @@@@@ loop that never closes. @@@@@ acquisition is done via repetitive exposure, but low-frequency words need to be @@@@@ in advance to stick. @@@@@ new @@@@@ inline for the first time breaks the flow of reading. Both @@@@@ can be resolved by sticking to "n+1" @@@@@ of @@@@@ difficulty, but I'd rather read nothing at all than educational @@@@@.
With this in mind, I decided to go against the grain of the near-universal advice to "learn to read by reading". The goal was 99% coverage, or die trying. I was going to stop reading, and shove the symbols into my head by force, like cornmeal tunneled down a foie gras duck's throat to fatten its diseased liver.
First, I would need a better feeder.
Observe
The flashcard site I was using was called Hack Chinese.1 The front side of each flash card was the word, the back its pronunciation and definition. In a separate interface there was a dictionary listing character etymology and stroke order.
I would end up copy-pasting interesting words into the dictionary window to pull up the word entry. SLOW!
I would then click on the component characters to open their nested dictionary entries. SLOW!
If I needed to remember the stroke order, I would scroll down for the static display. SLOW!
When I was well and truly stuck, I would open an LLM chat window and paste the word into an extended "Explain This Word" chat. SLOW!
How to FAST?
Replicate
I glanced at the huge expanse of empty white space in the back of the flashcard and had an idea: what if I never had to leave this window?
I opened Claude Code and started rambling into my mic. It wrote thousands of lines of questionably efficient JavaScript. I didn't read a single one.
I fed the beast whatever it needed. Character graphs by the Unicode consortium were traversed into one hundred thousand lines of phonetic mapping data. If I still couldn't understand at the end of the day, a morphology breakdown would be one keystroke and API call away. A guy on a forum had hired a calligrapher to write three thousand characters in ballpoint pen; I bet that calligrapher never expected an LLM pipeline to eat the videos for regurgitation and redisplay.
The extension injection was fragile, proprietary, and platform-specific2. The beauty of the dawn of agentic coding was that I didn't care; it was so easy.
Optimize
The existence of information is useless without clean, rapid access to that information.
I matched border radii and background colors until the injected panels were pixel-flush with the original interface. Hues, alignment, font weights, everything needed to be in the right place. The keyboard layer grew until I needed both hands to operate it. E for etymology, C for calligraphy, T for tones, numbers to select characters...
Eventually selecting which information to display wasn't the bottleneck either - loading it was. I couldn't figure out how to speed up the morphology LLM call; if the calligraphy video ran at more than double speed, I'd lose track; opening the dictionary required a new browser tab.
It was already in the same place. Why not the same time? While the API call was happening, I could kick off the dictionary lookup in a permanent dummy window, then flip to the video, then the morphology breakdown would be back from API to close the loop.
What used to take upwards of 30 seconds now took less than one. At this point keystrokes were no longer the limiting factor, as my brain was being firehosed with information. In one sleepy haze, I considered optimizing my brain out of the loop.
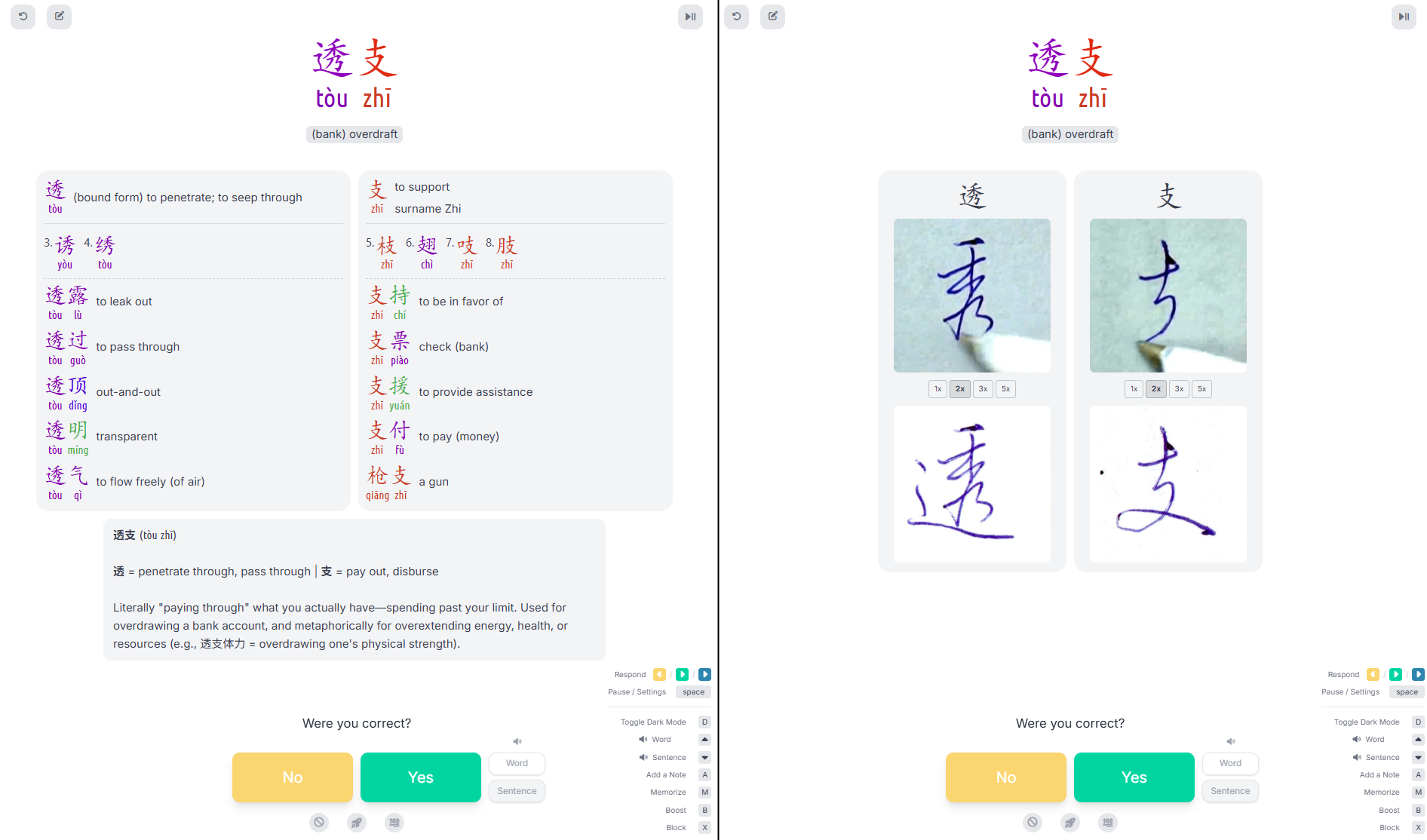
I had my feeder. I was about to be addicted.