Chinese: Cursed Logographic DAGs
Logographic
I started learning how to read and write Chinese recently. In that time, I have often wanted to strangle the language by its metaphorical throat. In this blog post, I will explore the reasons behind my metaphysical hatred, and how I learned to redirect that hatred to thinking about linguistics.
IANAL (I am not a Linguist).
There are roughly four major types of writing systems. Three of them have funny names, and the fourth is demonic.
- Alphabet, like English. Every fundamental symbol (grapheme) maps to a sound (phoneme). Easy.
- Abjad, basically like an alphabet, except vowel phonemes are omitted in written representation. Arabic is a canonical example.
- Abugida (see? very fun to pronounce). There are base consonants that get modified with vowels. Often graphemes get combined for a phoneme representation. Devanagari writing system (for e.g. Hindi) is the most common.
- Logography...
Logography is basically hieroglyphs. Logographies are usually compositional, which means that you can combine mini hieroglyphs into big hieroglyphs. The most monstrous Chinese character biáng is for a kind of noodle:
𰻝
The only extant logography at scale is Chinese, and various derivatives thereof. The compositional structure means every character is a little dependency graph, so naturally I started thinking about them like DAGs.
DAGs
why DAGs?
A dependency graph is directed and, mercifully, in the Chinese logography also acyclic.
What are my nodes? They're characters. The whole character is the root node.
What are my edges? Now that is a question.
I refer to my homie 许慎 Xǔ Shèn, who in roughly the year 100 AD broke it down for us proletariat. Note that when I indicate EDGES, implicit is that there is a new character composed of those edges, so a new node.
- (NODE) 象形 xiàngxíng — pictograms. If you squint hard enough, 山 kind of looks like a mountain.
- (NODE) 指事 zhǐshì — ideograms. 一,二,三 is literally one, two, three. Don't ask about four.
- (EDGES) 会意 huìyì — compound ideograms. Combining meanings. 日 means sun, 月 means moon, 日 + 月 = ”bright“.
- (EDGES, 80%+ of all characters) 形声 xíngshēng — phono-semantic compounds.
The idea is basically that each leaf character can contribute either phonetics, semantics, or rarely both to its parent character. When some characters act as leaf nodes, they get simplified into more compact versions.
For example, 猫 (māo, cat). The semantic component is 犭, an abbreviated form of 犬 (dog) - yes, cat character uses dog radical. The phonetic component is 苗 (miáo, sprout), which donates its sound: miáo → māo. Then 苗 itself is a compound ideogram: 艹 (grass) over 田 (field).
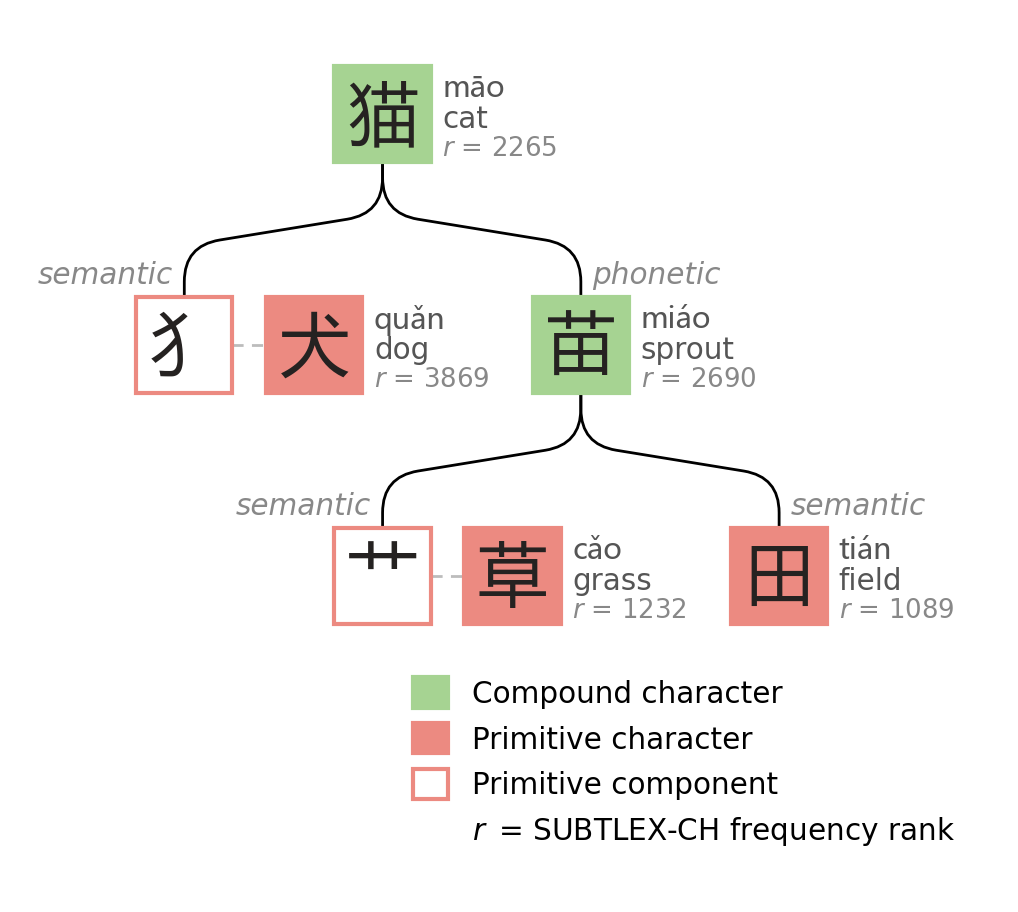
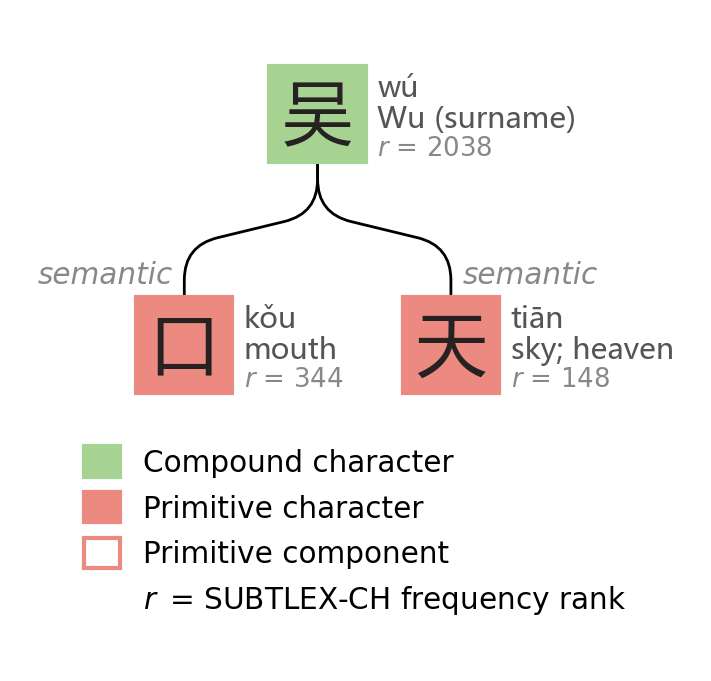
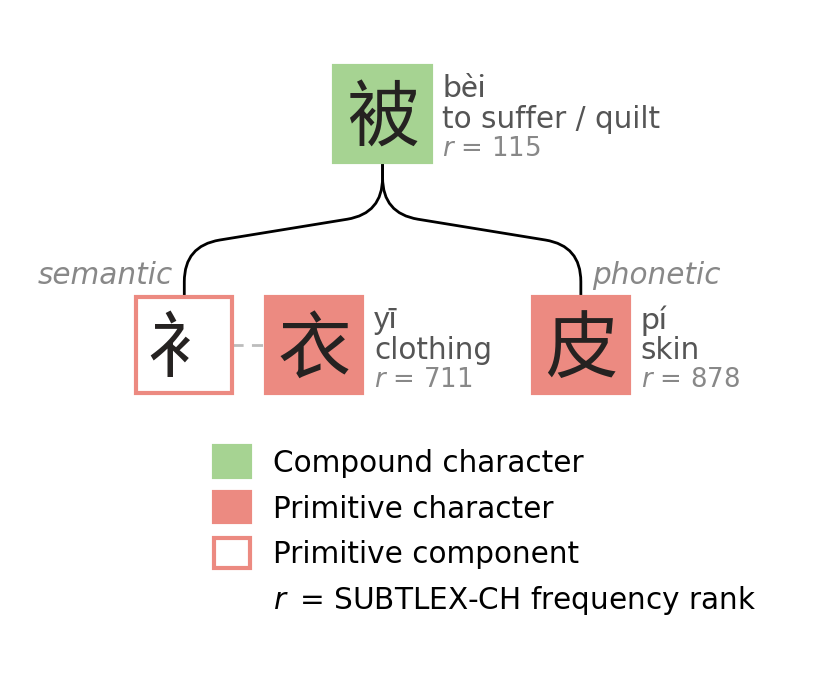
All decomposition diagrams in this post are my own, heavily inspired by the visual style in Loach & Wang1 with some extensions. Frequency rank r (lower = more frequent) from SUBTLEX-CH.2
topology
Every character is its own little DAG. However, components are shared, so the individual DAGs overlap into one big network. Li & Zhou3 effectively moralize (undirect) this graph and project it into the component layer. Then they analyze the resulting undirected graph.
They have many big brain insights. Here are ones I thought were important:
- The graph is a small world network, so it is generally highly clustered and has low distances.
- Learning transfers locally and not globally - mastering a set of compounds associated with one component is not going to help very much with others.
- Semantic components are hubs with a high degree, and phonetic components are low degree.
- Semantic components should probably be emphasized a bit more than phonetic components when we see both in a character.
- The phono-semantic compounds can be modeled as a bipartite graph, with semantic radicals on one side, phonetic radicals on the other, and characters as edges.
- Phono-semantic compounds are a good model for learning and Xǔ Shèn had a point.
Doesn't sound bad so far, right? Just you wait.
Cursed
cursed phonetics
The phonetic edges are arguably more cursed than semantic edges. Only about a quarter to a third of phonetic edges reliably predict pronunciation.4 This is because the phonetic edges are not based on modern Standard Chinese Mandarin pronunciation. Various phonetic edges were added at different times, but the best overall match for the phonetic edge composition is Old Chinese ... which nobody speaks anymore and is about 2,000 to 3,000 years old.5
A canonical argument is that words share a phonetic component if they could have rhymed (strictly speaking, rimed) in the Book of Odes (詩經, Shijing), dating from the 11th to 7th centuries BC.5 Which was apparently edited by Confucius. Picture below.

Fortunately, modern Mandarin Chinese pronunciation still has some remnants of old Chinese. If we fudge with tones and have some heuristics for mapping various consonant sounds to each other, it's possible to squeeze some juice out of even unreliable phonetic edges.
Consider 皮 (pí, skin). Several characters use 皮 as their phonetic: 被 (bèi), 披 (pī), 破 (pò), 疲 (pí). In modern Mandarin, only 疲 still matches exactly. If we inspect their pronunciations though: pí, bèi, pī, pò, the initials are all bilabial plosives (p, b). The exact sounds drifted over three millennia, but the consonant family survived.
Beyond phonetic decay, a second difficulty is that Chairman Mao decided to simplify the character system in the 1950s and 60s. The thought process was that to encourage mass literacy among a then mostly rural population, one had to tame some complex beasts of the compound logographic system and render them simpler and easier to memorize. Keep in mind that the literacy rate was approximately 20% at this time and mostly concentrated among the urban elite.
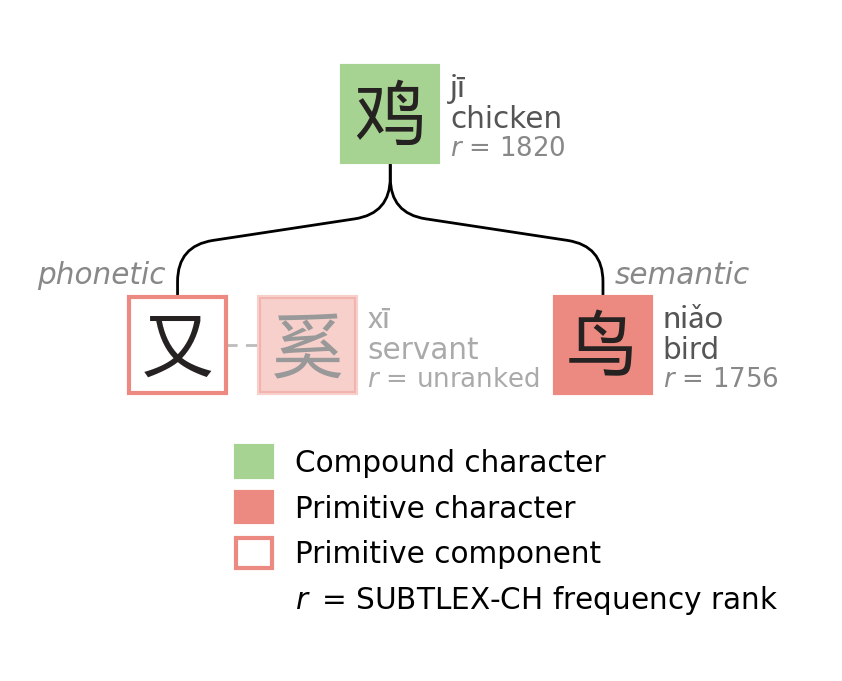
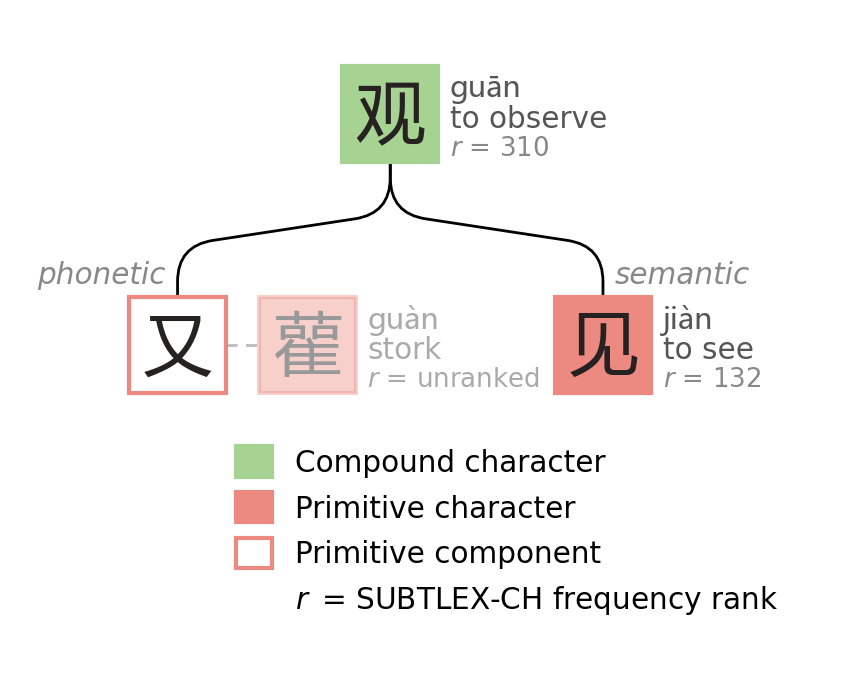
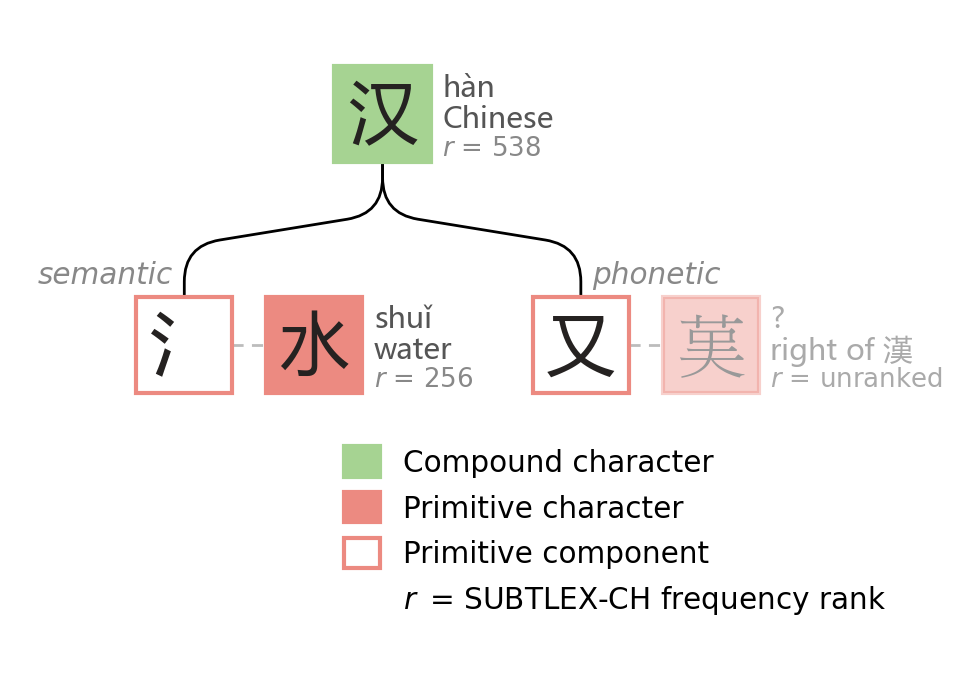
In this process, some components were mapped to the exact same simplified component. For example, "this phonetic component is too complicated, just swap it with 又 (yòu, again)."
The dashed lines below show what 又 replaced in 鸡, 观, and 汉; wildly different phonetic components flattened to 又. For 汉, the original right side of 漢 was so esoteric that there isn't even an isolated component to point back to. I needed a fallback font to generate the diagram! The phonetic information passing through lossy compression of component substitution cannot be easily recovered at decompression time.
cursed semantics
I explained earlier, from the graph analysis, that the semantic components are hubs, and thus very valuable. But the semantic components are not always good boys. Sometimes they are very, very naughty.
One problem is that most semantic components are derived from Chinese concepts in antiquity. There are a multitude of concepts relating various kinds of cooking tools, eating implements, weapons, farm tools, and farmed/foraged plants.
The character 融 (róng, to melt) contains 鬲 (lì), a pictograph of a three-legged cooking vessel from the literal Bronze Age. Leaf nodes comprised of such nonsense are a not infrequent occurrence.
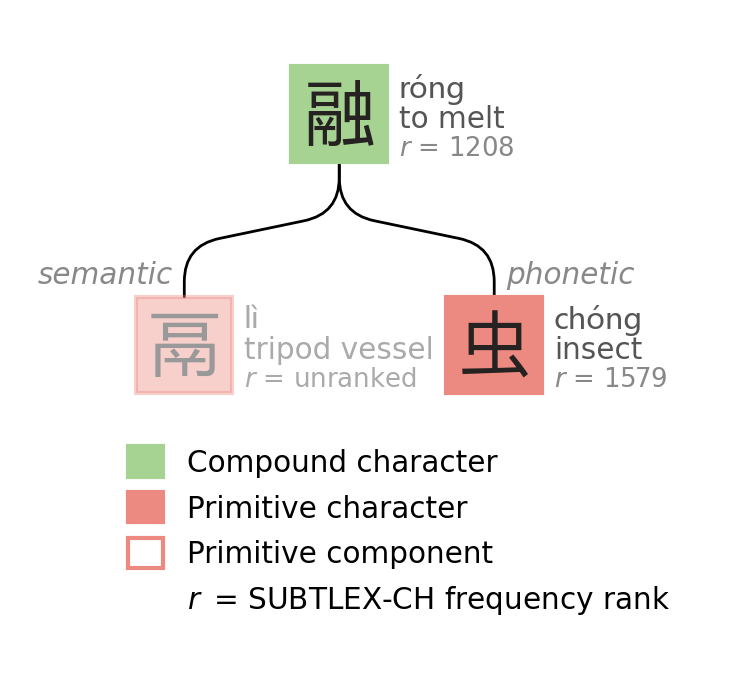

鬲 (lì) - that boi is THICC. Metropolitan Museum of Art, CC0.
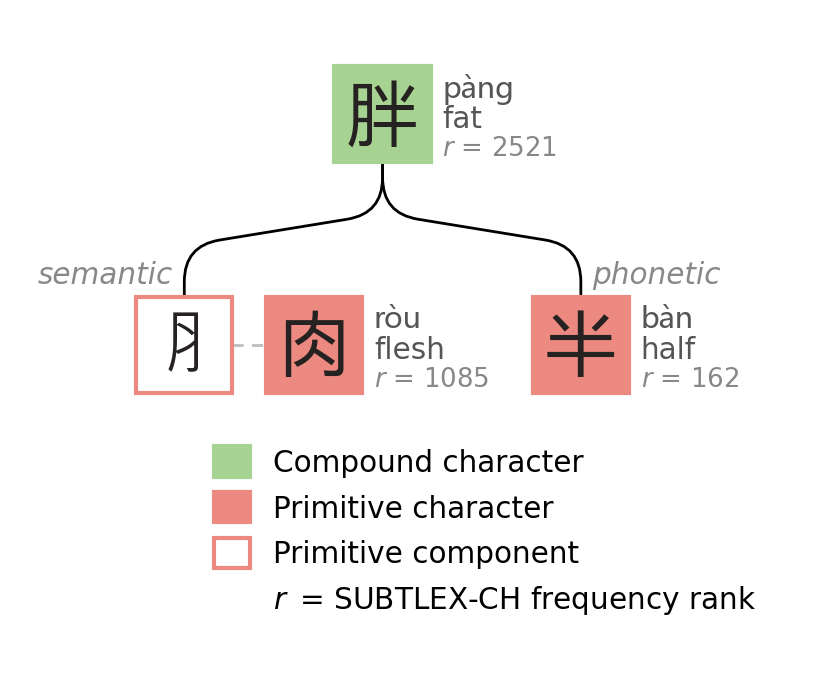
Worse, some components have been visually merged. Take 胖 (pàng, fat). Its semantic component looks like 月 (yuè, moon), but is actually ⺼, an abbreviated form of 肉 (ròu, flesh). This is not specific to 胖. Every character with a flesh/body radical (腿, 脑, 肝, 胃, ...) looks like it contains "moon", so I repeatedly have to decide from context whether it has something to do with the moon or something to do with meat.
Cope
How should I order my learning of characters? Loach & Wang1 recommend reordering characters so that learners encounter leaf nodes before their parent nodes. They balance this against usage frequency, so that rare components don't jump the queue over useful characters.
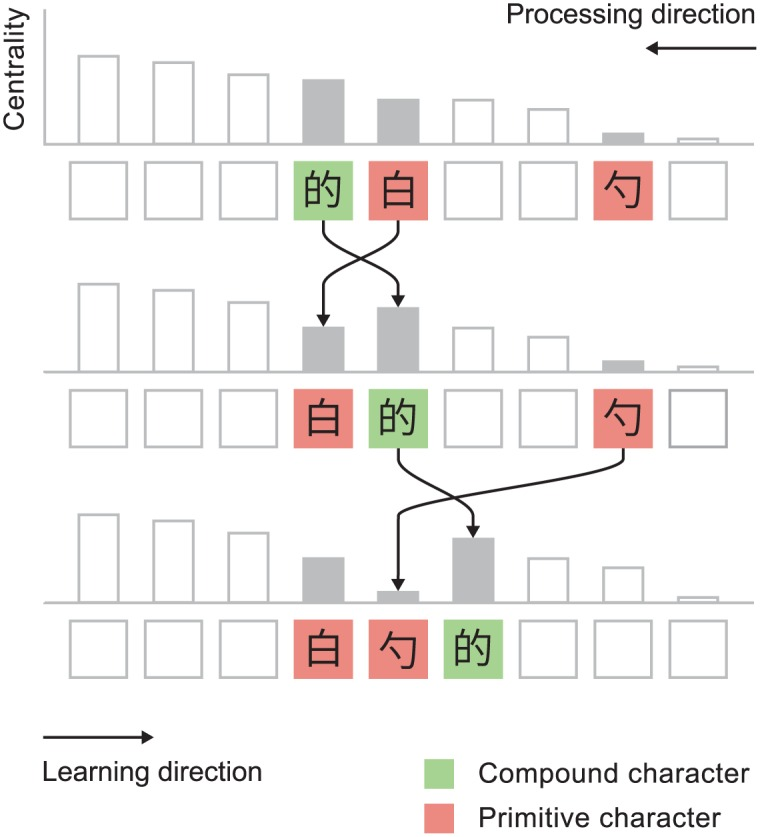
Figure from Loach & Wang.1 "The ordered list is processed from low to high centrality (right to left in the figure). Once 的 is reached, its components are checked in turn. 白 is found to lie to the right of 的 and so is repositioned to its left. Likewise 勺 is found to the right of 的 and is similarly repositioned. 勺 is positioned to the right of 白 because it has lower centrality. The centralities used in this figure are for illustrative purposes only."
I think this is a bit hopelessly optimistic. The official word lists provided by the Chinese government for language testing excessively violate this character learning order. High-frequency characters have cursed components that really should not be scheduled out in front. I think the heavy lifting has to be done by the learner if I want to approach things from a graph-focused perspective.
The spaced repetition tool I started with was Hack Chinese, which partnered with Outlier Linguistics to provide phonetic and semantic component analysis in its dictionary. I didn't think much of it at the time. Then, reading Loach & Wang,1 I hit this line in the methodology: "based on a preliminary version of forthcoming dictionary by Outlier Linguistic Solutions." I got exceedingly lucky that baby's first language learning tool was already DAG-based.
When I see a new character, I mentally apply the following recursive depth-first search, propagating meaning and sound back up from the leaves:
procedure normalize(component):
if component is already a full character:
return component
else:
map abbreviated form back to its full character
return full character
procedure decompose(character):
components = get_components(character)
for each component in components:
normalized = normalize(component)
if normalized is opaque, meaning I can't understand it quickly:
if the parent character is very important:
memorize the component via supplementary mnemonic
else:
give up, skip
else if normalized can be decomposed further:
decompose(normalized)
record what this component contributes:
semantic?
phonetic?
combine the contributions from all components
now I understand semantics and phonetics of the character
This took me to literacy in a couple of months. YMMV. The graph is cursed, but it's the only graph we have.
If you have some familiarity with the Chinese language, you are probably screaming internally at me right now that I have not explained one of the most important parts of the writing system. Yes, I have to leave a note at the end. Actually, Chinese characters are combined to form words. In linguistics terms, the logographic morphemes combine into lexemes. Usually these words are two characters.
I, however, have rambled on for long enough, and so if you are interested in words, go search somewhere else.
Loach J, Wang J. Optimizing the learning order of Chinese characters using a novel topological sort algorithm. PLOS ONE. 2016;11(10):e0163623. https://pmc.ncbi.nlm.nih.gov/articles/PMC5051716/↩
SUBTLEX-CH is a character frequency list built from subtitles of roughly 6,000 Chinese films. Lower rank is more frequent.↩
Li J, Zhou J. Chinese character structure analysis based on complex networks. Physica A. 2007;380:629–638. https://www.sciencedirect.com/science/article/abs/pii/S0378437107002105↩
Hsiao JH, Shillcock R. Analysis of a Chinese phonetic compound database: Implications for orthographic processing. Journal of Psycholinguistic Research. 2006;35(5):405–426. https://link.springer.com/article/10.1007/s10936-006-9022-y↩
Hill NW, List J-M. Using Chinese character formation graphs to test hypotheses about Chinese historical phonology. Bulletin of Chinese Linguistics. 2019;12(2):186–215. https://brill.com/view/journals/bcl/12/2/article-p186_186.xml↩